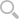
截止2019-9-7,自己收集《一起来捉妖》的相关数据已有四个月啦!且也完成了数据的收集、分析以及呈现的过程。计划将该部分信息及时传递给“想要修炼数据分析之术和深入浅出的思考”的你,协助你更快、更好地完成数据分析产品的入门和实战训练,以及提升你的数据分析之术和思考。
2018年,当时我正在研究区块链是什么?恰巧听到腾讯将发布一款基于区块链技术的游戏——《一起来捉妖》。由于该游戏的开发位于成都,我并不能拿到第一手的内测权限。故此只能等该产品公测时才能体验这款带有区块链技术的游戏产品。
截止2019年4月15号左右,调研发现很多小伙伴的手机里安装了一款游戏软件——《一起来捉妖》,我才得知它早已将区域公测拓展到全区公测的层面。我也从App Store下载了《一起来捉妖》,决定开启区块链游戏的历程。与此同时,我怀抱着对该款游戏的热爱决定收集《一起来捉妖》更新最频繁的活动模块入手,从大局上看产品制作者的角度看用户的想法。
很多人说:《一起来捉妖》是中国版的《精灵宝可梦》。故此我需要将这两款产品的相对共有的信息提炼出来,方便我们使用对比的方法观察二者之间的关系,如:
不可否认,两款产品有太多的相似之处。除了发布时间不一样以外,我认为《一起来捉妖》确实是一款贴近国内市场的角色扮演和奇幻冒险的游戏;且还是敢于在应用中尝试使用新技术——区块链技术,并完成落地。
同时,我通过百度搜索分别检索《一起来捉妖》和《精灵宝可梦Go》的关键词,然后发现精灵宝可梦Go的最新相关信息如下:
而一起来捉妖的最新相关信息如下:
我们从二者的最新相关信息可直观看出,《一起来捉妖》正在处于产品的打磨和产品推广的阶段;《精灵宝可梦Go》处于营收变现疯狂上升的阶段。不过我们从时间上来看:《精灵宝可梦Go》已经运营了三年之久,此时已经成为游戏运营者的摇钱树;而《一起来捉妖》刚运营满一年,游戏开发者正在急速打磨产品功能,远不知它的营收什么时候才能跟《精灵宝可梦Go》相提并论。
不过我愿意通过不断完善收集的数据,持续跟踪和记载它们运营中发生的里程碑事件,帮助大家推断《一起来捉妖》两年后的获得的答案是什么。
在确定收集数据之前,我会按照以下三步进行原始数据的提取。如:
由活动板块衍生出的方向主要有三个:产品官网、产品本身、百度指数。
通过制定方向发现,大家可以发现:我遵循着产品信息的生产地——产品信息的落实地——监控产品信息的路径。
本次将收集数据的时间定为:每周周五的晚间十点。
为什么要指定收集时间呢?只有这样,我们才会保证收集的兴趣递增,不至于对数据收集产生嫉妒的厌恶感。倘若丢失收集的兴趣,数据的质量也将会大大降低,那么离我们分析数据的初衷也就会背道相驰。
怎么来指定收集的时间呢?主要依据时间维度和数据体量来选择相对合适的收集数据的节点。
分析原因:《一起来捉妖》官网的新闻资讯更新速度并不快,以一周为时间周期,以适中的维度为信息体量,将此作为收集数据的模式,最后为该模式限定一个具体的时间点去收集数据。
本次将收集的数据存储在:专属的Excel表格中。对于表格结构,我认为做到自己喜欢的风格,且便于寻找查询就可以。
我的表格中存储信息有:新闻资讯的时间和标题等信息记录,产品终端的新颖的功能或活动截图,百度指数数据统计数据统计截图。
我认为处理数据的过程与收集数据的过程是不可分离的。
切记:在数据处理过程中,我们脑海中的数据是间歇性输出的过程,我们提前筹划给数据处理预留出足够的拓扑空间。在数据处理过程中,尽量按照自己理解的来处理。
在组建数据标题栏的时候,我们就应该时刻考虑,我们会从哪些方面处理收集的数据?单个层面下面应该包含多少子属性以及可扩展的属性等?我们不能控制住数据生产的源头,但是却有权利为它们置入我们所理解的标签,将它们变成我们想要的数据。
推荐阅读:旗龙