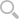
快手建设 HBase 差不多有2年时间,在公司里面有比较丰富的应用场景:如短视频的存储、IM、直播里评论 feed 流等场景。本次只分享其中的一个应用场景:快手 HBase 在千亿级用户特征数据分析中的应用与实践。为什么分享这个 Topic?主要原因:对于大部分公司来说,这都是一个普适的场景,因为很普遍,所以可选择的分析引擎也非常多,但是目前直接用 HBase 这种分析用户特征的比较少,希望通过今天的分享,大家在将来遇到这种场景时, 可以给大家提供一个新的解决方案。
本次分享内容包括:
▌业务需求及挑战
1. 业务需求
用一句话来概括业务需求:在千亿级日志中,选择任意维度,秒级计算7-90日留存。
如上图所示。左边是原始数据,可能跨90天,每一天的数据可以看作是一张 Hive 宽表,在逻辑上可以认为每行数据的 rowkey 是 userId(这里不严谨,userId 可能是重复的),需要通过90天的原始数据计算得到右边的表,它的横轴和纵轴都是日期,每个格子表示纵轴日期相对于横轴日期的留存率。
该需求的挑战:
2. 技术选型
面对这些问题,我们当时的技术选型:
① Hive,因为大部分数据可能是存在 Hive 里,可以直接写 SQL 计算,该方案不用做数据迁移和转换,但是时延可能是分钟到小时级别,因此否定了这个方案。
② ES,通过原始数据做倒排索引,然后做一个类似计算 UV 的方式求解,但是在数据需要做精确去重的场景下,它的耗时比较大,需要秒到分钟级。
③ ClickHouse,ClickHouse 是一个比较合适的引擎,也是一个非常优秀的引擎,在业界被广泛应用于 APP 分析,比如漏斗,留存。但是在我们的测试的中,当机器数量比较少时 ( <10台 ),耗时依然在10秒以上。
立足于这种场景,是否存在其它解决方案,延迟可以做到2-3秒(复杂的场景10秒以下),同时支持任意维度组合?基于 HBase,结合业界简单/通用的技术, 我们设计并实现了 BitBase 解决方案,用很少的资源满足业务需求。
▌BitBase 解决方案
1. 数据模型
如上图所示,首先将原始数据的一列的某个值抽象成 bitmap(比特数组),举例:city=bj,city 是维度,bj (北京) 是维度值,抽象成 bitmap 值就是10100,表示第0个用户在 bj,第1个用户不在北京,依次类推。然后将多维度之间的组合转换为 bitmap 计算:bitmap 之间做与、或、非、异或,举例:比如在北京的用户,且兴趣是篮球,这样的用户有多少个,就转换为图中所示的两个 bitmap 做与运算,得到橙色的 bitmap,最后,再对 bitmap 做 count 运算。count 表示统计“1”的个数,list 是列举“1”所在的数组 index,业务上表示 userId。
2. BitBase 架构
整个 BitBase 架构包括五部分:
3. 存储模块
推荐阅读:旗龙